AI Has Gotten Cheap — Here’s How to Find the Best Cost Effective LLMs
Cost effective LLMs are no longer a compromise. The best ones now match near-flagship performance at a fraction of the price.
Here’s a quick look at the top options:
| Model | Input (per 1M tokens) | Output (per 1M tokens) | Best For |
|---|---|---|---|
| Grok 4 Fast | $0.20 | $0.50 | Lowest cost, high accuracy |
| GPT-5 Mini | $0.25 | $2.00 | Coding, reasoning, speed |
| Gemini 2.5 Flash | $0.30 | $2.50 | Long docs, multimodal |
| DeepSeek V3 | ~$0.28 | ~$0.84 | Cost-sensitive workloads |
| Claude Haiku | $0.80 | $4.00 | Summarization, chat |
Most business owners assume powerful AI is expensive. That assumption is outdated.
LLM inference costs have dropped roughly 50x per year over the past few years. A query that once cost dollars now costs fractions of a cent. In fact, running a typical informational query through a model like Gemini 2.5 Flash costs about 1/25th the price of a Bing Search API call.
The challenge isn’t cost anymore. It’s knowing which model to use, when, and how to structure your usage to keep bills predictable as you scale.
This guide breaks down the top cost effective options, compares real performance benchmarks, and shows you exactly how to deploy AI without overpaying.

Introduction
In the early days of generative AI, “cheap” meant “incompetent.” If you wanted a model that could actually reason or code, you had to pay a premium. But the frontier of cost effective LLMs has moved faster than almost any other sector in tech.
To understand the scale of this shift, we have to look at inference costs—the price we pay to get an answer from the model. Median price declines have hit about 50x per year recently. For context, GPT-4 level science questions are now roughly 40x cheaper to answer than they were just a short time ago.
When we compare this to traditional web search APIs, the math is startling. A “raw” search result API call from a provider like Brave costs between $5 and $9 per 1,000 queries. Google’s “Grounding with Google Search” feature is priced at $35 per 1,000 queries. Meanwhile, a typical LLM query of 500–1,000 tokens on a model like Gemini 2.5 Flash costs between $0.0002 and $0.0004.
We aren’t just seeing a slight discount; we’re seeing a fundamental restructuring of how information is processed. This price-performance frontier allows us to build agentic workflows that were previously cost-prohibitive. However, navigating this landscape requires an understanding of tokenization—the way models “read” text. Since 100 tokens roughly equal 75 words, your choice of model and how it handles subword units (like BPE or SentencePiece) can swing your monthly bill by 20% or more.
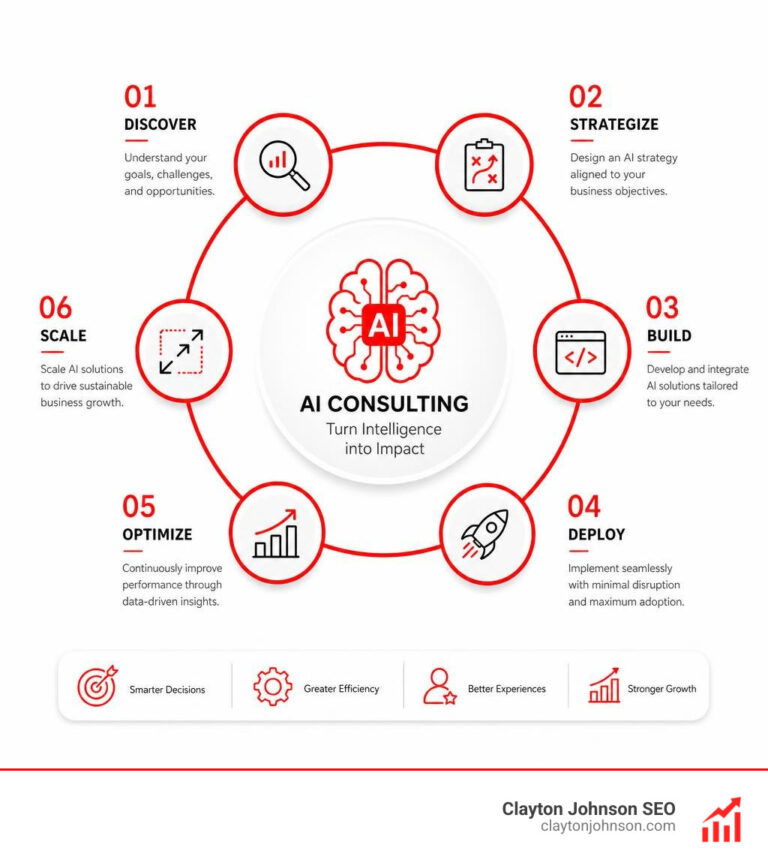
Top Contenders for Cost Effective LLMs

When we evaluate cost effective LLMs, we aren’t just looking for the lowest price tag. We’re looking for “intelligence density”—the most reasoning power per dollar spent.
The Heavy Hitters
- Grok 4 Fast: Currently leading the pack in pure price-performance. It is up to 64x cheaper than early GPT-3 models while maintaining a staggering 92.0% accuracy on AIME math contests.
- GPT-5 Mini: OpenAI’s response to the efficiency wars. It responds roughly 40% faster than the flagship GPT-5 while retaining over 91% accuracy on high-level reasoning tasks.
- Gemini 2.5 Flash: Google’s efficiency king. With a massive 1-million-token context window, it’s the go-to for analyzing massive legal briefs or technical manuals at a fraction of the “Pro” model’s cost.
- DeepSeek V3: A major disruptor from the open-weights community. Research suggests their API pricing has about 80% margins on GPU costs, proving that these low prices are sustainable and not just subsidized “races to the bottom.”
- Claude 3.5 Haiku: While slightly more expensive than the “Mini” or “Flash” variants, it often surpasses previous-generation flagship models in creative writing and nuance.
To make an informed choice, you need to look at more than just the headline price. You must don’t overpay for intelligence: how to choose cost-effective LLMs by matching the model’s strengths to your specific task. For instance, if you need real-time data, you’ll need to factor in Gemini API pricing and grounding costs which can add significant overhead.
| Model | Context Window | AIME Math Score | Best Use Case |
|---|---|---|---|
| Grok 4 Fast | 128k | 92.0% | High-volume logic |
| GPT-5 Mini | 128k | 91.1% | Coding assistants |
| Gemini 2.5 Flash | 1M+ | 85.0%+ | Long doc analysis |
| DeepSeek V3 | 128k | 89.3% | Data extraction |
| Claude Haiku | 200k | 75.0%+ | Customer chat |
Benchmarking Performance of Cost Effective LLMs
It is a common myth that cheap models are “dumb.” Modern benchmarks tell a different story. In the AIME (American Invitational Mathematics Examination) contest, models like GPT-5 Mini and Grok 4 Fast are scoring in the 90th percentile—territory once reserved for only the most massive, expensive clusters.
However, we must be careful with these numbers. As we’ve discussed before, why most LLM leaderboards are actually bullshit is because they often measure memorization rather than true reasoning. To find a truly cost effective LLM, we look at “reasoning tokens.” Models like the o1 series or GPT-5 Mini generate internal “thinking” tokens to solve complex problems. While these are billed as output tokens, they significantly increase the accuracy of the final answer.
Recent scientific research on inference economics of language models shows that for 90% of business tasks—like summarization, classification, and basic data extraction—the performance gap between a $0.20/1M token model and a $15.00/1M token model is negligible.
Architectural Drivers of Cost Effective LLMs
Why is this happening so fast? It isn’t just better hardware; it’s smarter math.
- Mixture-of-Experts (MoE): Instead of activating the whole model for every word, MoE models only use a small “expert” slice of the neural network. This allows a model to have the knowledge of a giant but the “running costs” of a small model.
- Quantization: This is the process of reducing the precision of the model’s numbers (e.g., from 16-bit to 4-bit). It’s like shrinking a high-def video to 720p; it looks almost the same but takes up way less space and power.
- Sparse Attention: This allows models to “focus” on relevant parts of a prompt rather than processing every single word with equal weight, which is essential for handling those 1M+ context windows in Gemini Flash.
Understanding these drivers helps us how to assess LLM scalability for enterprise without breaking the bank by choosing architectures that fit our specific hardware or API constraints.
Total Cost of Ownership: API vs. Open Source
Many developers think that using an open-source (OSS) model like Llama 3.1 or Qwen is “free.” This is a dangerous trap. While you don’t pay a per-token fee to a vendor, you pay in “TCO” (Total Cost of Ownership).
Our research into OSS deployment scenarios reveals a sobering reality:
- Internal Tooling (Low Volume): Can cost $10k–$15k/month once you factor in GPU rental and the “fractional talent” needed to maintain the server.
- Customer-Facing (Moderate Scale): Jumps to $40k–$60k/month.
- Evaluation Hell: This is the hidden cost of OSS. Because new models drop weekly, teams spend hundreds of hours benchmarking and switching, leading to “talent fragility.”
If you don’t have a dedicated DevOps team, don’t make these AI selection mistakes by assuming self-hosting is cheaper. Often, a managed API is significantly more cost effective for everything but the highest-scale enterprise applications.
Strategic Implementation and Future Pricing Trends

The future of cost effective LLMs isn’t about finding one “god model.” It’s about orchestration. We are moving toward a world of “per-action billing” and SLA tiers.
For example, a customer support chatbot doesn’t need a $40/1M token reasoning model to say “How can I help you?” It can use a $0.05/1M token model like Qwen 2.5 for the greeting and only “escalate” to a GPT-5 or Claude 3.7 Sonnet when the user asks a complex technical question.
We also anticipate a shift toward commoditization. General-purpose text generation is becoming a utility, much like electricity or bandwidth. The real value—and the premium pricing—will shift toward specialized models with “extended thinking” budgets, like the Amazon Nova 2 Lite, which allows you to toggle between “low,” “medium,” and “high” reasoning budgets.
If you’re looking to build these systems, you might consider the ultimate guide to fine-tuning LLMs for marketing magic to create smaller, specialized models that outperform general ones at a lower cost. Or, if you need a custom roadmap, you can contact Clayton Johnson for AI strategy to build a growth engine that scales.
Maximizing ROI with Prompt Caching and Batching
If you want to slash your AI bill by 50–90% today, you need to master two things: Caching and Batching.
- Prompt Caching: Most providers (Anthropic, OpenAI, DeepSeek) now offer massive discounts (up to 90%) if you repeat the same “context” or “system prompt.” If you are sending a 2,000-word instruction manual with every query, caching ensures you only pay full price for it once.
- Batching: If your task isn’t urgent (e.g., summarizing yesterday’s sales transcripts), you can use “Batch APIs.” You send the requests and get them back within 24 hours at a 50% discount.
Understanding what LLM throughput benchmarks actually mean is key here. High throughput is great for batching, but low latency is what you need for a snappy chatbot.
Subscription Plans vs. API Pay-As-You-Go
For non-technical users, the choice is often between a $20/month subscription (ChatGPT Plus, Gemini Advanced) or using an API.
The “break-even” point is surprisingly high. To make a $20/month subscription “worth it” compared to a cost effective LLM API like GPT-4o mini, you would need to generate millions of tokens per month. For most casual users, the subscription is a “convenience tax.” However, for power users who need “unlimited” access to the absolute top-tier reasoning models (like o1 or Claude 3.7), the subscription is an incredible deal.
You can read my completely subjective comparison of the major AI models to see which “Pro” features actually justify the monthly cost for your workflow.

Conclusion: Building Scalable AI Systems
At Clayton Johnson SEO, we don’t just chase the newest, shiniest model. We focus on cost effective LLMs because they are the fuel for scalable growth engines.
True leverage comes from system-level thinking. By aligning your content architecture with the right AI models, you create a compounding growth loop where your operational costs stay flat while your output and traffic explode. Whether you are extracting data from 2 million patient records or building a coding assistant for your dev team, the goal is the same: Clarity → Structure → Leverage.
If you are ready to stop overpaying for “vanity” AI and start building durable, tool-backed systems, explore our more info about financial services growth systems or our strategy frameworks. The era of expensive AI is over. The era of smart, scalable implementation has just begun.





")