RAG & Vector Databases 101
Why RAG & Vector Databases Are the Foundation of Modern AI Systems
RAG & Vector Databases are the two core components that allow AI systems to retrieve accurate, up-to-date information from your own data — instead of relying solely on what an LLM was trained on.
Here’s a quick breakdown:
| Concept | What It Is | Why It Matters |
|---|---|---|
| RAG | A method that retrieves relevant data before generating a response | Reduces hallucinations, adds current knowledge |
| Vector Database | A database that stores data as numerical embeddings for semantic search | Enables fast, meaning-based retrieval at scale |
| Embeddings | Numerical representations of text or other data | Allow semantic similarity matching beyond keywords |
| Hybrid Search | Combines vector search with keyword search | Improves precision and recall together |
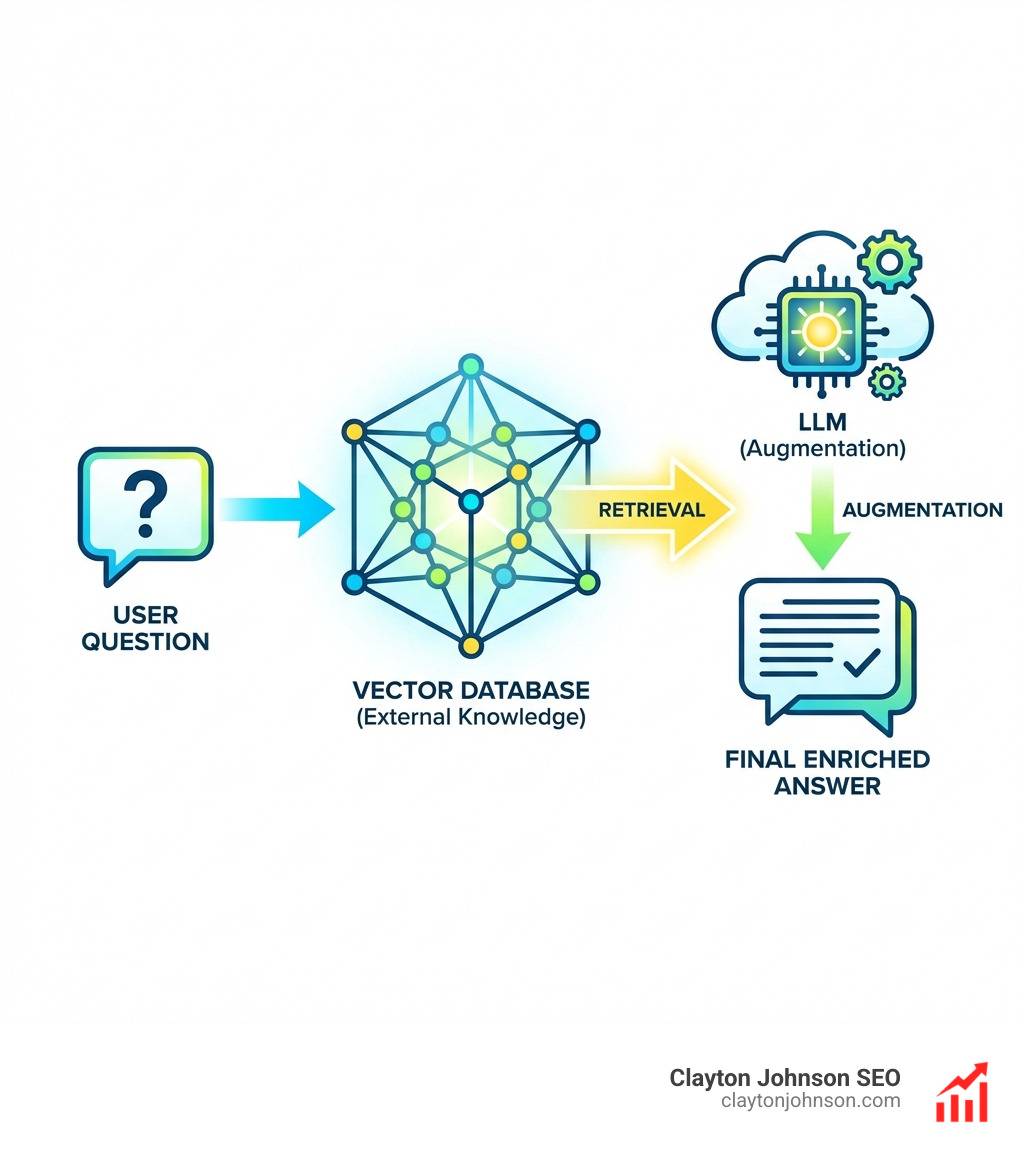
Large language models (LLMs) are powerful reasoners — but their knowledge is frozen at training time. Ask one about your internal docs, last quarter’s data, or a proprietary process, and it either guesses or hallucinates. RAG fixes this by pulling relevant context from an external knowledge source at query time and feeding it into the prompt. Vector databases make that retrieval fast and semantically accurate, even across millions of documents.
The result is an AI that can reason over your data — not just public internet content.
I’m Clayton Johnson, an SEO strategist and growth systems architect who works at the intersection of AI-assisted workflows and scalable content infrastructure — including designing and evaluating RAG & Vector Databases as part of enterprise AI stacks. In this guide, I’ll walk you through exactly how these systems work, which databases lead the field, and how to choose the right architecture for your use case.

Understanding RAG & Vector Databases
To understand why we need RAG & Vector Databases, we first have to admit that standalone LLMs are a bit like brilliant students who graduated five years ago and haven’t looked at a newspaper since. They are incredible at logic and language, but their “knowledge” is a static snapshot of the internet from whenever they were last trained.
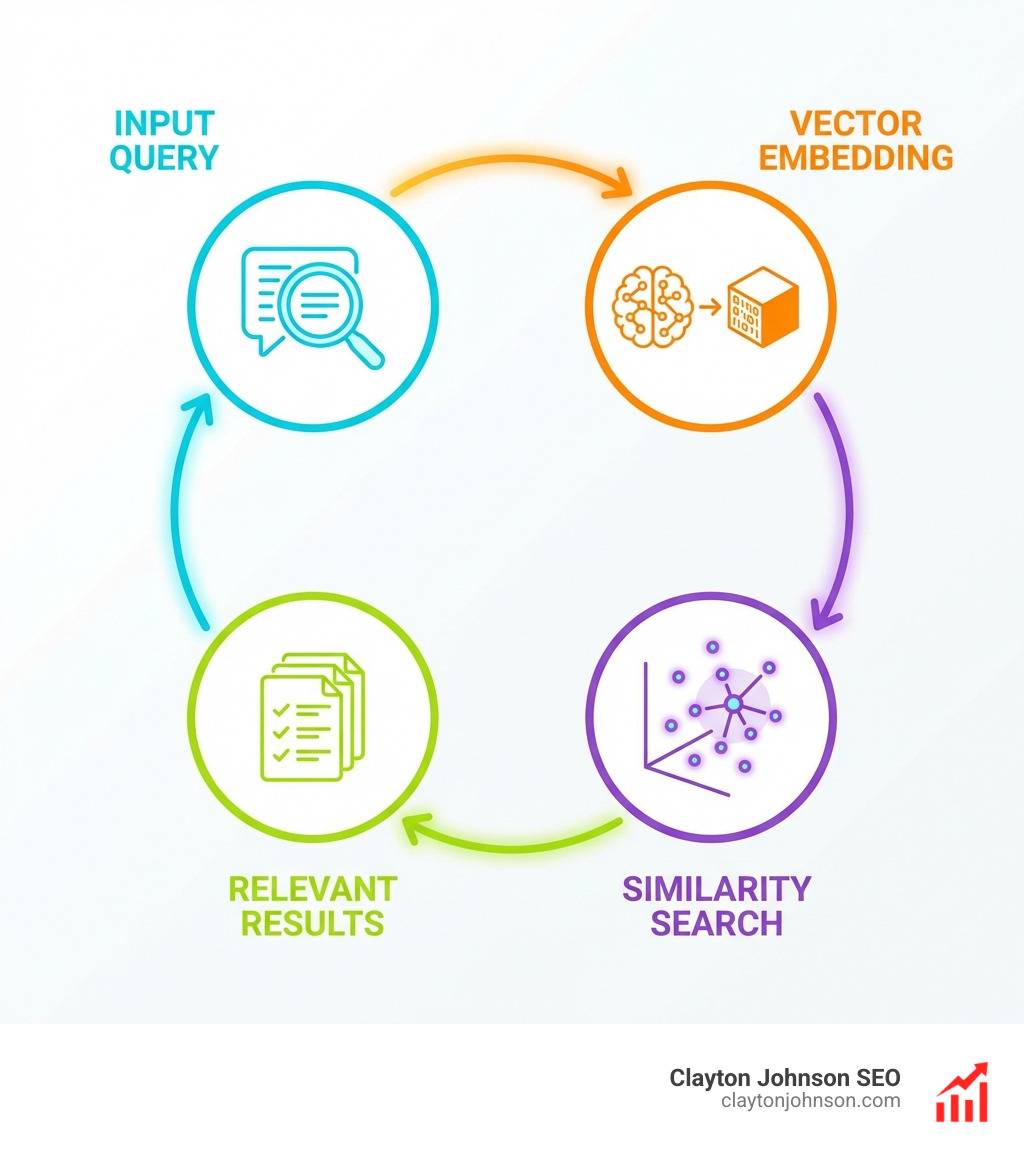
Retrieval-Augmented Generation (RAG) is the “open-book exam” for AI. Instead of forcing the model to memorize everything, we give it a library (your data) and a librarian (the vector database). When a user asks a question, the librarian finds the most relevant pages, hands them to the student, and says, “Use these to answer the question.”
The Power of Semantic Search
Traditional search engines look for keywords. If you search for “feline healthcare,” a keyword search might miss a document that only mentions “cat medicine.” Vector databases enable semantic search, which understands that “feline” and “cat” are conceptually the same. By mapping data into a high-dimensional “vector space,” we can find information based on its actual meaning.
Data Grounding and Proprietary Knowledge
For businesses in Minneapolis and beyond, the real value of AI isn’t in writing poems about cats; it’s in querying proprietary data. Whether it’s legal contracts, technical manuals, or customer support tickets, RAG & Vector Databases provide the “grounding” necessary to ensure the AI doesn’t just make things up. This architecture is a critical part of the AI ecosystem explained, as it bridges the gap between general-purpose models and specialized business needs.

Mechanics and Top Databases
Building a RAG system requires more than just dumping text into a folder. It involves a specific pipeline: document loading, chunking (breaking text into manageable pieces), embedding, and indexing.
When we talk about indexing, we often look at algorithms like K-Nearest Neighbors (KNN) or Approximate Nearest Neighbor (ANN). For massive datasets, we use Hierarchical Navigable Small Worlds (HNSW), which allows the database to skip through layers of data to find matches in milliseconds. According to scientific research on vector search indexes, choosing the right index is the difference between a system that scales to billions of records and one that crashes under the weight of a few thousand.
If you are building these systems, you will likely interact with them via APIs. Understanding the ultimate guide to running AI models via API can help you integrate your chosen database into your broader application logic.
| Database | Primary Strength | Best For |
|---|---|---|
| Pinecone | Fully managed, serverless ease | Teams wanting to move fast without managing infra |
| Milvus | Massive scalability (billions of vectors) | Enterprise-grade, distributed deployments |
| Weaviate | AI-native with built-in vectorization | Developers who want a “batteries-included” experience |
| Qdrant | High performance, Rust-based | Complex metadata filtering and memory efficiency |
How Embeddings Power RAG & Vector Databases
Embeddings are the secret sauce. They are long lists of numbers (vectors) that represent the “location” of a piece of text in a multi-dimensional map of human knowledge.
When we embed a sentence, we are essentially giving it a coordinate. If two sentences have similar coordinates, they are semantically related. This is measured using cosine similarity—the smaller the angle between two vectors, the more similar they are.
Managing these numerical representations requires the right toolkit. We recommend checking out the essential AI ML tools handbook to see how embedding models fit into the modern developer’s stack.
Choosing the Best RAG & Vector Databases for Your Stack
Selecting the right database depends on your specific constraints:
- Pinecone: The industry standard for “it just works.” Its serverless architecture means you don’t have to worry about shards or clusters.
- Milvus: If you’re dealing with a trillion vectors, Milvus is your best friend. It separates storage and compute, allowing for extreme scaling.
- Weaviate: We love Weaviate for its ability to store objects and vectors together, making it feel more like a traditional database while maintaining AI power.
- Qdrant: Excellent for those who need to filter results by metadata (like “only show documents from the Minneapolis branch”) without sacrificing speed.
- Redis: Known for ultra-low latency, making it perfect for real-time chatbots.
- pgvector: If you’re already using PostgreSQL, this extension lets you store vectors in your existing database, simplifying your architecture significantly.

Advanced Architectures and Enterprise Scale
As RAG systems move from “cool demo” to “enterprise utility,” we encounter new challenges: latency, throughput, and precision.
One of the most effective ways to improve retrieval is Hybrid Search. While vector search is great at finding “concepts,” it can sometimes miss specific technical terms or acronyms. Hybrid search combines vector similarity with traditional keyword matching (like BM25). This ensures that if a user searches for a specific error code, the system finds the exact match, while still understanding the broader context of the query.
Research on RAG benchmarking shows that the LLM generation itself is often the bottleneck for latency, but a poorly optimized vector database can add hundreds of milliseconds to every request. For organizations prioritizing performance, following AI infrastructure best practices is non-negotiable.
Graph-Based Retrieval for Complex Data
Traditional RAG & Vector Databases have a weakness: they treat data as isolated “chunks.” If you break a book into 500-word pieces, the system might lose the relationship between a character in Chapter 1 and an event in Chapter 20.
This is where Graph RAG comes in. Instead of just storing flat vectors, we store data as nodes and edges (relationships).
- TigerVector: A newer innovation that combines vector search with graph databases, achieving up to 5x higher throughput than older graph systems.
- Neo4j: A veteran in the graph space that has added robust vector indexing to support complex relationship mapping.
Using a Knowledge Graph API guide can help you understand how to implement these systems to preserve context. Furthermore, if you are building your own datasets to feed these graphs, tools like Firecrawl are invaluable—check out our complete guide to Firecrawl for AI builders for more.

Frequently Asked Questions
What is the difference between RAG and a vector database?
RAG is the process or architecture (Retrieve, Augment, Generate). A vector database is the tool used during the “Retrieve” step to store and find information. You can do RAG without a vector database (using keyword search), but it won’t be nearly as smart.
Why is hybrid search important for RAG?
Vector search is like a “vibe check”—it finds things that are conceptually similar. Keyword search is like a “fact check”—it finds exact matches. Combining them gives you the best of both worlds: the ability to understand meaning and the precision to find specific terms.
How do embeddings impact retrieval quality?
The quality of your embeddings determines how well your database “understands” your data. If you use a cheap or outdated embedding model, your search results will be irrelevant, leading the LLM to generate incorrect or “hallucinated” answers. Always use a high-quality, modern embedding model that matches your data’s domain.
Conclusion
Mastering RAG & Vector Databases is no longer optional for companies looking to leverage AI. It is the difference between a chatbot that hallucinates and an AI agent that provides genuine business value. By grounding your models in proprietary data and using advanced retrieval techniques like hybrid and graph-based search, you create a system that is both accurate and scalable.
At Clayton Johnson SEO and Demandflow.ai, we believe that clarity leads to structure, and structure leads to leverage. We don’t just focus on tactics; we build structured growth architecture. Whether you are optimizing your content for AI discovery or building internal AI tools, your success depends on a solid foundation.
If you’re looking to scale your authority and build an AI-enhanced execution system, our SEO services and growth frameworks are designed to help you achieve compounding growth. Let’s build the future of your business together.