Why Speed Defines the Future of AI Model Deployment
AI inference tools fal represent a new generation of infrastructure designed to solve the latency problem that plagues generative media applications. When developers build real-time AI features—whether generating images, video, or audio—every millisecond counts. Traditional inference platforms often force users to choose between speed, cost, and model diversity, creating bottlenecks that degrade user experience.
Quick Answer: What Are AI Inference Tools Fal?
- Platform: fal.ai is a generative media cloud specializing in ultra-fast inference for image, video, and audio models
- Founded: 2021 by Burkay Gur and Gorkem Yurtseven (ex-Coinbase and Amazon engineers)
- Key Advantage: Order-of-magnitude faster inference through globally distributed GPUs and custom CDN architecture
- Model Support: 600+ models including Flux, Wan Pro, Kling, and Minimax audio
- Enterprise Features: SOC 2 compliance, private endpoints, usage-based or reserved pricing
- Integration: Native support via Hugging Face InferenceClient and direct APIs
The challenge is simple: generative AI models require GPU power for inference, unlike traditional ML models. As Batuhan Taskaya, Head of Engineering at fal.ai, noted after implementing Tigris storage: they “ingested 10s of TBs of data in mere hours while storing 100+ TB without any hassle.”
This isn’t just about raw compute. It’s about architecture—how you minimize network hops, optimize model loading, and distribute inference geographically to serve users with sub-250ms cold starts. It’s why fal.ai built custom infrastructure rather than relying on standard web CDNs that weren’t designed for AI workloads.
I’m Clayton Johnson, and I’ve spent years helping companies build scalable technical content systems and evaluate AI infrastructure for production deployments. Throughout this guide, I’ll show you how ai inference tools fal differentiate themselves through distributed computing, storage optimization, and developer-first APIs that actually work at scale.
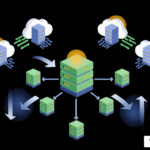
 User request arrives via HTTP/REST API or WebSocket, 2) Request routed to nearest GPU in global network, 3) Model loaded from optimized storage (or warm cache), 4) Inference executed with optional streaming, 5) Output uploaded to CDN in background thread, 6) Response returned to user with minimal latency. Key optimization points highlighted: geographic distribution, background processing, and parallel GPU utilization. - ai inference tools fal infographic")
The Evolution of Generative Media Clouds and AI Inference Tools Fal
To understand why fal.ai has become a darling of the developer community, we have to look at the landscape in 2021. Founders Burkay Gur and Gorkem Yurtseven didn’t set out to build a “media cloud” initially. Their background at Coinbase and Amazon gave them a front-row seat to the massive gaps in ML infrastructure.
Originally, the team focused on optimizing Python runtimes to speed up general machine learning compute. However, the world shifted overnight with the explosion of DALL-E and ChatGPT. Suddenly, every developer wanted to generate high-fidelity media, but the infrastructure was stuck in the “batch processing” era. If you’ve ever tried to run a heavy diffusion model on a standard cloud instance, you know the pain: long wait times, complex setup, and unpredictable costs.
We see fal.ai as the bridge between academic research and production-grade software. They’ve evolved into a specialized generative media cloud that treats speed as a first-class citizen. By obsessing over the “GPU crunch”—the period where GPU capacity was scarce and generation times were abysmal—they built a platform that handles the heavy lifting of model deployment so we can focus on building features.
For a deeper dive into how this fits into the broader landscape, check out the-ultimate-guide-to-running-ai-models-via-api.

Solving the Latency Gap in Generative AI
The “latency gap” is the difference between a user clicking “Generate” and seeing a result. In a world of instant gratification, a 30-second wait time is a conversion killer. AI inference tools fal solve this by optimizing every layer of the stack.
Standard web infrastructure is built for static files and simple text requests. It isn’t built for ingesting 10s of TBs of data or streaming multi-gigabyte model weights into VRAM. By building a custom inference engine and a specialized CDN, fal.ai ensures that the user-to-GPU hop is as short as possible.
The Mission Behind AI Inference Tools Fal
The mission is simple: developer empowerment. Gur and Yurtseven realized that most AI teams were spending 80% of their time on infrastructure and only 20% on the actual product. By providing a unified hub for the world’s most advanced models, they’ve lowered the barrier to entry for startups and public companies alike. Whether you’re a solo dev or a hypergrowth startup in Minneapolis, the goal is to make AI inference as reliable as a standard database query.
Technical Architecture: Shaving Milliseconds Off Every Request
If you want to know why fal is “just crazy fast,” you have to look under the hood. Most providers simply rent out GPUs and give you an API. Fal, however, has built a globally distributed network of GPUs.
The architecture is designed to minimize the number of “hops” a request takes. When a user in the Midwest sends a request, it shouldn’t have to travel to a data center in Europe and back. Fal routes the request to whichever GPU is closest and available, utilizing a custom-built CDN that understands AI workloads.

For more on how this compares to other platforms, read our guide on inference-platforms-that-wont-make-you-grow-a-beard-while-waiting.
Optimizing AI Inference Tools Fal for Real-Time Media
One of the coolest tricks in the fal playbook is how they handle output. While the GPU is finishing the final steps of an image generation, fal starts the upload process in the background. Shaving off those extra milliseconds from the image upload phase means the user sees the result almost instantly after the inference finishes.
They also constantly benchmark their production models against state-of-the-art (SOTA) research. If a new architecture or optimization technique (like FP8 quantization) can reduce generation time without sacrificing quality, it gets implemented.
Distributed Computing and Multi-GPU Workflows
For massive tasks, a single GPU isn’t enough. Fal provides a DistributedRunner and DistributedWorker framework that allows us to scale inference across multiple GPUs (e.g., 4x H100s) simultaneously.
This is particularly useful for video models or high-resolution image upscaling. By using torch.distributed integration, fal handles the “world size” and “rank” management, allowing developers to focus on the model logic.

Specialized Model Support: From Flux to Video Generation
Fal isn’t just about speed; it’s about having the right tools for the job. They host over 600 models, covering everything from text-to-image to 3D generation.
State-of-the-Art Image and Video Pipelines
The star of the show recently has been Flux, the largest SOTA open-source text-to-image model built by the original Stable Diffusion team. Fal was their first choice for optimization, ensuring it runs on production-grade endpoints with minimal latency.
But the platform has also become a powerhouse for video. With models like Wan Pro Video Generation and Kling, fal is positioning itself as the “video-first” inference cloud. These models are notoriously heavy, but fal’s infrastructure handles the complex sequencing and memory requirements needed for smooth video output.
We also use these tools to process massive amounts of data. If you’re interested in how this feeds back into the AI cycle, see the-art-of-turning-the-web-into-ai-datasets.
Storage Efficiency with Tigris Integration
Storage is often the hidden cost of AI. Storing 100TB+ of generated media and model weights can bankrupt a startup if they’re paying high egress fees to traditional cloud providers.
Fal partnered with Tigris Data to solve this. By using Tigris, they saved 85% on object storage costs compared to other clouds. This cost efficiency is passed down to us, the users, keeping the platform affordable even at massive scale.

Comparing AI Inference Tools Fal with Industry Alternatives
No guide is complete without a side-by-side look at the competition. While fal.ai is our top pick for generative media, other tools like Runpod and Together AI have their own strengths.
Fal.ai vs. Runpod and Together AI
| Feature | fal.ai | Runpod.io | Together AI |
|---|---|---|---|
| Specialization | Generative Media (Image/Video) | On-demand GPUs / Serverless | Open-source LLMs |
| Pricing | Usage-based & Reserved | Hourly / Per-second | Per-token / Hourly |
| Cold Starts | < 250ms (Optimized) | Variable (Container-based) | Very Low (Managed) |
| Complexity | Low (Ready-to-use APIs) | Medium (Requires Docker) | Low (API-driven) |
| Best For | Real-time apps, Media gen | Training, custom workloads | LLM chat, RAG systems |
Runpod is fantastic if you need raw “bare metal” access or want to launch your own custom Docker containers. However, fal.ai wins on the “developer experience” front for media tasks because the models are already optimized and ready to go. Together AI is the leader for LLMs, but they don’t focus as heavily on the specialized diffusion pipelines that fal excels at.
For help deciding on your company’s overall direction, see our enterprise-ai-strategy-101.
Fal.ai vs. NVIDIA Triton Inference Server
NVIDIA Triton is the gold standard for enterprise-level model orchestration. It’s an open-source server that handles multiple frameworks (PyTorch, ONNX, TensorRT). The trade-off is complexity. Setting up a Triton cluster requires significant DevOps expertise.
Fal essentially gives you “Triton-level” performance without the headache of managing the underlying Kubernetes clusters or hardware. If you’re a massive enterprise with a dedicated AI platform team, Triton is the way to go. If you’re a product team that needs to move fast, ai inference tools fal are the better choice.
Enterprise-Grade Deployment and Scalability
As companies grow, “fast” isn’t enough. It has to be secure and compliant. Fal has invested heavily in enterprise features that make it suitable for public companies and high-security environments.
- SOC 2 Compliance: Essential for enterprise procurement and data security.
- Private Endpoints: Ensure your data never touches the public internet.
- Single Sign-On (SSO): Managed access for large teams.
- Usage Analytics: Real-time tracking of costs and performance metrics.
Building a responsible AI stack is about more than just speed; it’s about safety. See our guide on building-a-responsible-ai-framework-5-key-principles-for-success.
Integrating AI Inference Tools Fal with Hugging Face
One of the best ways to use fal is through the Hugging Face ecosystem. Hugging Face’s InferenceClient allows you to select fal-ai as the provider with a single line of code.
This gives you the best of both worlds: the massive model library of Hugging Face and the ultra-low latency of the fal inference engine. You can even set policies like :cheapest or :fastest to let the system automatically route your requests based on your current priorities.
Developer Tools and Real-Time Streaming
For apps that require a “live” feel, fal provides raw WebSockets. This allows for real-time streaming of inference progress. For example, if you’re generating an image, you can stream intermediate “latents” to show the user a blurry preview that sharpens as the generation completes.
Frequently Asked Questions about Fal.ai
How does fal.ai handle global GPU distribution?
Fal uses a custom-built CDN and a globally distributed network of GPUs. When a request comes in, it’s routed to the nearest available GPU node to minimize network latency and “hops.” This architecture is specifically optimized for large binary data (like model weights and generated images) rather than just text.
What are the primary pricing models for fal.ai?
Fal offers two main paths:
- Usage-based: You pay only for the compute you use. This is perfect for startups and apps with fluctuating traffic.
- Reserved Capacity: For high-volume users, you can reserve dedicated GPUs. This ensures guaranteed capacity and often results in lower per-inference costs at scale.
Does fal.ai support custom model hosting?
Yes. While fal is known for its library of 600+ pre-optimized models, enterprise users can deploy and serve their own custom models securely. This includes private model endpoints and one-click fine-tuning for models like Flux or Stable Diffusion.
Conclusion
The shift toward multimodal AI—where images, video, and audio are generated as fluidly as text—requires a fundamental rethink of infrastructure. AI inference tools fal have successfully carved out a niche by obsessing over the details that matter to developers: speed, reliability, and ease of use.
By combining globally distributed GPUs with smart storage solutions like Tigris and a deep integration into the Hugging Face ecosystem, fal.ai has moved from a simple optimization tool to a comprehensive generative media cloud. Whether you’re building the next viral social app or an enterprise marketing suite, these tools provide the foundation for a truly “real-time” AI experience.
At Clayton Johnson SEO, we help founders and marketing leaders navigate these technical shifts to build high-growth content systems. If you’re looking to leverage AI in your growth strategy, explore our SEO content marketing services or dive deeper into our strategy frameworks.
The future of AI isn’t just about what the models can do—it’s about how fast they can do it. And with tools like fal, “fast” is finally catching up to our creativity.