Why How assess LLM scalability enterprise Matters Before You Commit to a Model
How assess LLM scalability enterprise is a critical decision framework every founder and marketing leader needs before deploying AI at scale. Here is a quick answer:
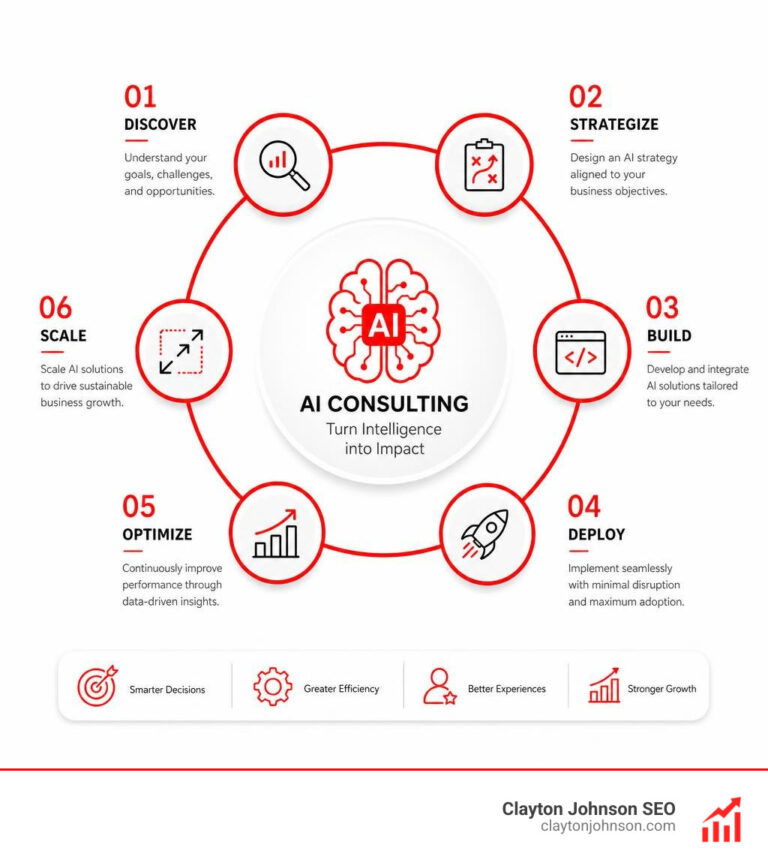
To assess LLM scalability for enterprise use, evaluate these six dimensions:
- Token efficiency – Compare actual token consumption across your real workloads, not just per-token pricing
- Latency and throughput – Measure time-to-first-token (TTFT) and tokens-per-second under realistic concurrency
- Cost at volume – Model daily and annual costs using your actual query volume and language mix
- Reliability and uptime – Test fallback routing, error rates, and SLA consistency under load
- Domain accuracy – Evaluate against your specific use cases, not public leaderboard benchmarks
- Infrastructure fit – Assess gateway overhead, deployment model (API vs PaaS vs self-hosted), and MLOps integration
Generative AI spending is growing fast, but the failure rate of enterprise AI projects sits at roughly 95%. That gap tells the real story. Most teams pick a model based on benchmark scores, launch a proof of concept, and then watch costs spiral or performance collapse when real workloads hit production.
The problem is not the technology. It is the evaluation process.
Public benchmarks like MMLU or GPQA test models in isolation. But your enterprise deployment is never just a model. It is a model plus prompts, retrieval systems, guardrails, user interfaces, and human workflows. None of that complexity shows up on a leaderboard.
One clear example: tokenizer efficiency alone can drive up to a 450% difference in costs between models handling the same workload. A financial services team processing 100,000 daily customer inquiries could see daily AI costs jump from $100 to $450 simply by choosing the wrong model.
That is not a performance problem. That is a selection problem.
I’m Clayton Johnson, an SEO and growth strategist who works at the intersection of technical systems and scalable marketing infrastructure. My work on AI-augmented workflows and structured growth architecture gives me a direct lens on how assess LLM scalability enterprise decisions compound into either leverage or liability over time.

Quick look at How assess LLM scalability enterprise:
The Primary Dimensions of LLM Scalability
When we look at how assess LLM scalability enterprise, we have to move past the “wow” factor of a single chat response. Scaling means moving from one user to ten thousand concurrent users without the system catching fire or the CFO having a heart attack.
The primary dimensions of scalability fall into three buckets: Performance, Cost, and Reliability.
- Performance: This isn’t just about accuracy. It’s about throughput (how many tokens the system can pump out per second) and latency (how long the user waits for that first word to appear).
- Cost: Enterprise scaling is where “cheap” models become expensive. You must account for token consumption, infrastructure overhead, and the labor cost of maintaining the system.
- Reliability: Can the system handle 300 requests per second (RPS)? Does it have a fallback if the primary provider goes down?
To truly understand your options, you need to look at technical metrics through a business lens. A model that is 5% more accurate but 10x slower might actually destroy your ROI by frustrating users.
Comparison of Deployment Models
| Feature | Off-the-Shelf API | Platform as a Service (PaaS) | Self-Hosting (Open Source) |
|---|---|---|---|
| Setup Speed | Instant | Moderate | Slow |
| Data Control | Provider-dependent | High | Maximum |
| Maintenance | Low (Provider handles) | Moderate | High (Team handles) |
| Cost Structure | Pay-as-you-go | Subscription + Usage | High CapEx / GPU costs |
| Scalability | High (Elastic) | High | Limited by hardware |
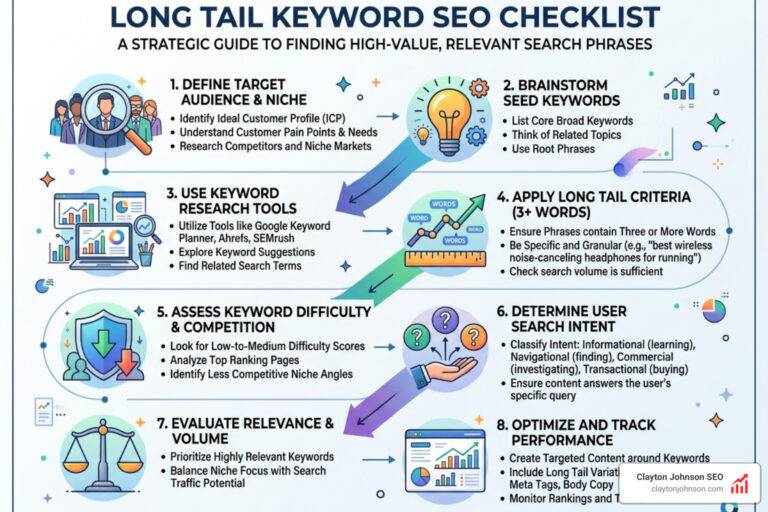
How assess LLM scalability enterprise through Token Efficiency
One of the most overlooked aspects of how assess LLM scalability enterprise is tokenizer performance. Every LLM “sees” text as tokens, but they don’t all slice the pie the same way.
Research shows up to a 450% variance in token usage between different model tokenizers for the exact same sentence. If you are operating in a multilingual environment—say, handling customer support in English, Spanish, and Tamil—this gap widens. Some tokenizers are highly inefficient with non-English characters, turning a simple phrase into a massive pile of expensive tokens.
For a global ecommerce company, this efficiency gap could mean the difference between a $15,000 annual AI bill and a $31,000 bill. You can use tools like OpenAI’s Tokenizer to get a baseline, but always test your specific domain data.
Evaluating Infrastructure and Gateway Performance
In a production environment, you rarely call an LLM directly. You use an LLM Gateway. This is a proxy layer that handles things like rate limiting, authentication, and model routing.
When we evaluate how should Enterprises evaluate LLM Gateway for Scale?, we look for ultra-low latency. A poorly built gateway can add 50ms to 100ms of overhead. High-performance gateways, like those built on Rust, can handle 250+ RPS with only about 3ms of latency overhead.

Building a Strategic Framework to How assess LLM scalability enterprise
Scaling isn’t just a technical hurdle; it’s a strategic one. We recommend a “Balanced Scorecard” approach. This means you don’t just look at whether the model is “smart.” You look at whether it is sustainable.
Why Public Benchmarks Fail to Predict Real-World Success
We’ve all seen the leaderboards. Model X beats Model Y on the MMLU or GPQA benchmarks. But here is the secret: public benchmarks are often “contaminated.” Because the models are trained on the open internet, they have likely already seen the questions and answers in those benchmarks.
Furthermore, a McKinsey study highlights that technical metrics often fail to translate into business impact. A model might be great at solving math riddles (MMLU) but terrible at following your company’s specific brand voice or navigating your internal database.
Essential Technical Metrics to How assess LLM scalability enterprise
To get a real sense of production readiness, you need to track these specific metrics:
- Time to First Token (TTFT): How long does the user wait before the text starts appearing? For internal tools, every 100ms of latency can lead to a drop in productivity.
- Time Between Tokens (TBT): Once it starts, does it flow smoothly or stutter?
- Prompt Perplexity: This measures how “confused” a model is by your instructions. Lower is better.
- Uncertainty: This quantifies the model’s confidence in its own response. If uncertainty is high, you might need better RAG (Retrieval-Augmented Generation) data.
To move beyond generic testing, we use strategic evaluation frameworks that align these numbers with your business goals, like reducing support ticket volume or increasing SEO content output.

Cost-Effective Evaluation: Automating the LLM-as-a-Judge
The old way of evaluating LLMs was to have a human sit down and grade 500 responses. That doesn’t scale. It’s slow, subjective, and expensive.
The new way is “LLM-as-a-Judge.” This involves using a highly capable model (like GPT-4) to grade the outputs of a smaller, faster model. But even this can get pricey. At a million evaluations a day, GPT-4 can burn through $2,500 daily just in “grading” costs.
This is where specialized evaluators come in. Research on the Luna-2 evaluator shows a 97% cost reduction compared to using GPT-4 for evaluations, without losing accuracy. This allows you to test every single interaction in your pipeline rather than just a small sample.
Agentic and RAG-Specific Scalability Metrics
As we move toward “Agentic” AI—where models don’t just talk, they do things—we need new metrics.
- Tool Selection Quality: Did the AI pick the right tool (like a calculator or a database search) for the job?
- Action Completion: Did the AI actually finish the task, or did it get stuck in a loop?
- Chunk Utilization: In RAG systems, are we feeding the model the right “chunks” of data, or are we wasting tokens on irrelevant info?
MLOps Integration and Continuous Monitoring for Scale
Scaling is not a “one and done” event. Models drift. Data changes. What worked yesterday might hallucinate tomorrow.
You need a robust Trace system to see the entire lifecycle of a request, from the user’s prompt to the final output. This visibility is essential for debugging when things go wrong at scale.
Effective Dataset management and Experimentation functionality allow your team to test new prompts or model versions in a “sandbox” before pushing them to thousands of users. This is the difference between a professional AI operation and a “hope for the best” approach.

Implementing Guardrails and Runtime Protection
In an enterprise setting, safety is non-negotiable. One hallucinating agent can leak sensitive data or damage your brand reputation.
Runtime Protection acts as a real-time safety net. It intercepts inputs and outputs to ensure they meet your standards. For example, PII detection can automatically redact social security numbers or credit card info before they ever hit the LLM or get shown to a user.
Frequently Asked Questions about How assess LLM scalability enterprise
What are the hidden costs of poor LLM selection?
The biggest hidden cost is the “Productivity Tax.” If a model is 10x slower than its competitor (as some versions of Llama have been compared to proprietary models), your employees spend more time waiting and less time doing.
Then there are the token spikes. An inefficient tokenizer can cause a 450% increase in token usage. If you are processing millions of tokens, that “small” inefficiency turns into a six-figure mistake. Finally, multilingual degradation means you might have to build entirely separate pipelines for different regions, doubling your maintenance work.
How do I measure business outcomes like CSAT and NPS?
Technical metrics like “perplexity” don’t mean much to a CEO. To prove ROI, you must link AI performance to business KPIs:
- CSAT/NPS: Are customers happier with the AI’s answers?
- Task Time Reduction: Does the AI help employees finish work 30% faster?
- Ticket Volume: Has the AI successfully deflected 20% of support calls?
If your technical evaluations aren’t moving these needles, you aren’t scaling—you’re just spending.
Which tools provide enterprise-grade evaluation at scale?
Several platforms have emerged to handle the heavy lifting of how assess LLM scalability enterprise:
- Galileo: Excellent for high-volume production monitoring and low-cost automated evaluations. You can Get started with Galileo to see how they bridge the gap between technical and business metrics.
- Future AGI: Known for its research-first approach and specialized RAG metrics like context relevance.
- Arize: A leader in observability and drift detection.
- MLflow: A classic in the ML world that has expanded into GenAI tracking.
- Patronus AI: Specifically focused on hallucination detection and safety.
Conclusion
Scaling AI in the enterprise isn’t about finding the “smartest” model on a leaderboard. It’s about building a robust, cost-effective, and safe infrastructure that can grow with your business.
At Demandflow, we believe that clarity leads to structure, and structure leads to compounding growth. Whether you are building AI-augmented marketing workflows or complex SEO architectures, the way you how assess LLM scalability enterprise will determine your long-term success.
Don’t let your GenAI project become part of the 95% failure rate. Use a structured strategy, measure what matters, and build for the long haul.
Ready to build your growth architecture? Clayton Johnson is here to help you turn AI tactics into a structured growth engine.






")