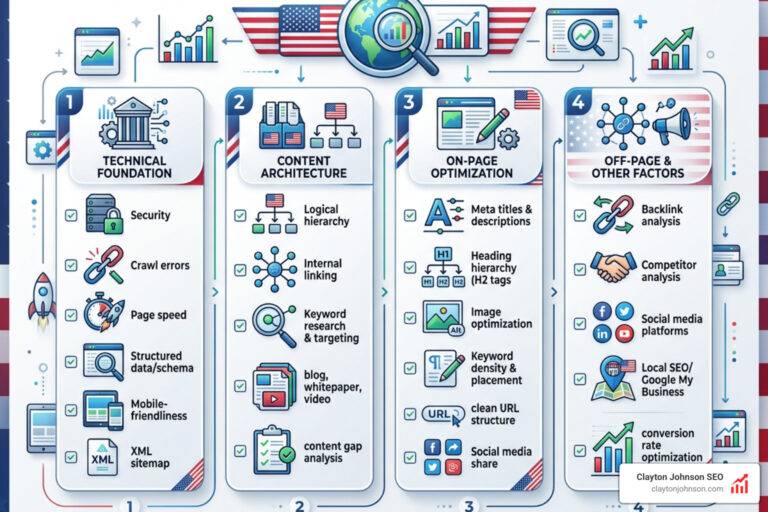
How test enterprise models the right way comes down to five core steps:
- Define success criteria aligned to your business goals, not just accuracy scores
- Select the right metrics — precision, recall, F1, latency, fairness, and hallucination rate
- Test with representative data that reflects real-world enterprise conditions and edge cases
- Validate the full system — not just the model, but integrations, endpoints, and workflows
- Monitor continuously for model decay, data drift, and performance regressions in production
Most enterprise AI projects don’t fail because the model is bad. They fail because the testing approach is wrong.
Teams confuse impressive demo performance with production readiness. A model can score well on a benchmark and still break under real workloads, generate biased outputs, or drift silently over time. According to Google’s ML engineering research, ML model code often represents only 5% or less of the total codebase in a production system — the rest is infrastructure, data pipelines, monitoring, and serving logic. Testing only the model misses 95% of what can go wrong.
The stakes are real. Poor validation leads to spiraling inference costs, rising latency, compliance failures, and projects stuck permanently in the proof-of-concept phase.
I’m Clayton Johnson, an SEO and growth strategist who works at the intersection of AI-assisted workflows, structured content architecture, and measurable business outcomes — including helping teams understand how test enterprise models as part of building scalable, ROI-driven systems. In the sections ahead, I’ll walk you through a practical, structured framework for enterprise AI model testing that goes well beyond basic accuracy checks.

How test enterprise models terms simplified:
The Foundation Model Fallacy: Why General AI Fails in Production
There is a massive hype cycle surrounding large foundation models. While these general-purpose tools are impressive for writing poems or summarizing generic articles, they often fall flat when dropped into a complex enterprise environment. This is known as the “Foundation Model Fallacy.”
In an enterprise setting, models encounter “brittle” scenarios. A foundation model lacks the specific business logic, internal terminology, and contextual depth required to handle a multi-step ERP workflow or a highly regulated legal document. Growing enterprise investment in AI is showing no signs of slowing, but many projects remain stuck in the pilot stage because general AI cannot bridge the gap between “cool demo” and “reliable tool.”
To solve this, we advocate for purpose-built models. These are often smaller, highly specialized models trained on minimal, high-quality data. For instance, a 30-billion-parameter diagnostic model trained on just 5,000 specific data samples can outperform massive models like Claude within days. By focusing on domain expertise and training data optimization, you reduce the “noise” that plagues consumer-grade AI.

A Holistic Framework for How Test Enterprise Models
To truly understand how test enterprise models, we must distinguish between model evaluation and system testing. Evaluation is what data scientists do in the lab to tune hyperparameters; system testing is what engineers do to ensure the AI doesn’t crash the entire platform.
| Feature | Model Evaluation | System Testing |
|---|---|---|
| Focus | Mathematical performance (Precision/Recall) | End-to-end reliability and user experience |
| Dataset | Golden datasets (static) | Real-world production traffic (dynamic) |
| Stage | Development/Training | Deployment/Production |
| Goal | Find the “best” version of the model | Ensure the system meets business objectives |
Using Golden Datasets and Synthetic Data
A “Golden Dataset” is a curated collection of high-quality examples that represent the “ground truth.” When learning how test enterprise models, these datasets are your North Star. However, real-world data is often messy or scarce (especially in fraud detection). In these cases, we use synthetic data to simulate edge cases and “break” the model before a customer does.
Tools like AI Test Model Generation allow teams to transform natural-language requirements into visual models, identifying gaps in coverage early. This holistic evaluation ensures that even non-deterministic behavior—where the AI might give slightly different answers to the same prompt—is bounded within acceptable limits.
Defining Success: Metrics Beyond Basic Accuracy
Accuracy is a vanity metric in the enterprise. If a fraud detection model is 99% accurate but misses the 1% of transactions that represent $50 million in theft, the model is a failure. Instead, we look at:
- Precision and Recall: Does the model find all the relevant cases without flagging too many false positives?
- F1-Score: The harmonic mean of precision and recall.
- Fairness and Ethics: Does the model discriminate against specific demographics?
- Hallucination Rate: How often does the model make up facts?
- Semantic Coherence: Does the output actually make sense from start to finish?
For deeper insights into what senior tech leaders are tracking, the TechLeader Enterprise AI Insights report highlights that business impact (like CSAT or ROI) is becoming the primary metric for AI success.
Technical Validation: How Test Enterprise Models for Scalability
One of the biggest economic pitfalls in enterprise AI is GPU dependency. Running massive models on high-end hardware is expensive and often unnecessary. Research shows that 95-98% of testing tasks can actually run on smaller, CPU-optimized models. This drastically reduces inference costs and latency.
We also need to monitor for “Model Decay.” This happens in three ways:
- Data Drift: The incoming data changes (e.g., a new type of customer joins the platform).
- Concept Drift: The relationship between data and the target changes (e.g., what was considered “normal” behavior is now “fraudulent”).
- Upstream Instability: A data source or API that the model relies on breaks.
Validated models, such as those found in the Red Hat AI Ecosystem Catalog, are tested for stable latency under concurrent traffic to ensure they meet Service Level Objectives (SLOs).
, Concept Drift (changing patterns), and Upstream Instability (broken pipelines) with clear icons and red warning signals - How test enterprise models infographic")
Advanced Methodologies: From A/B Testing to Bandit Algorithms
Once a model is deployed, the testing doesn’t stop. We use advanced statistical methods to compare performance in the wild.
- A/B Testing: Comparing the “Champion” model against a “Challenger” version.
- A/A Testing: Running the same model against itself to validate that your experiment design is sound and to estimate variance.
- Multi-arm Bandits: A more efficient way to test where the system automatically routes more traffic to the better-performing model over time, balancing exploration (learning) and exploitation (earning).
When implementing these, teams should use The ML Test Score Rubric to quantify production readiness. This rubric covers 28 specific tests, from feature distribution checks to canary testing.
Beware of Simpson’s Paradox: This occurs when a trend appears in different groups of data but disappears or reverses when the groups are combined. For example, a model might look better on “Day 1” and “Day 2” separately, but look worse overall if the traffic allocation changed mid-experiment. Always report confidence intervals to ensure your results are statistically significant.
Building a Robust Testing Infrastructure
Enterprise testing requires more than just a few scripts. It requires a structured growth architecture. We integrate AI testing into standard tools like Selenium for UI automation and JMeter for performance testing.
In large organizations, frameworks like SAFe (Scaled Agile Framework) help coordinate these efforts across multiple teams. The goal is a CI/CD integration where every code change triggers a suite of unit and integration tests for the AI pipeline.
Transitioning to Autonomous Testing: How Test Enterprise Models for ROI
The ultimate goal is to move from manual checks to autonomous testing. By using context-aware AI, we can achieve:
- Increased Test Coverage: Testing scenarios that humans might miss.
- Lower Maintenance Overhead: Self-healing tests that don’t break when the UI changes slightly.
- Better ROI: A 5% increase in customer retention (driven by better AI personalization) can raise profits by up to 95%.
By using CPU-optimized, specialized models, enterprises can avoid the “GPU trap” and scale their testing suites to thousands of daily runs without breaking the bank.
Frequently Asked Questions about Enterprise AI Testing
How do you handle non-deterministic results in enterprise models?
Since generative AI can give different answers to the same prompt, we use “bounded testing.” We define a range of acceptable outputs or use a second, “Scoring AI” to evaluate the quality of the first AI’s response based on predefined rubrics.
How often should enterprises re-evaluate deployed models?
Re-evaluation should be triggered by three things: a significant shift in data distributions (detected via monitoring), a change in business regulations, or at regular intervals (e.g., monthly) to check for silent model decay.
What is the difference between model evaluation and model validation?
Evaluation is a technical process focused on model performance (how well does it predict?). Validation is a business process focused on fitness for use (is it the right tool for this specific business problem?).
Key Takeaways And Next Steps
Knowing how test enterprise models is the difference between a successful digital transformation and a wasted investment. At Clayton Johnson SEO, we believe that clarity leads to structure, and structure leads to compounding growth. Through Demandflow.ai, we help founders and marketing leaders build the structured growth architecture needed to leverage AI effectively.
Whether you are optimizing your SEO strategy or building complex automated workflows, your AI is only as good as the framework you use to validate it. Don’t build for the hype; build for the future with a context-rich, measurable testing strategy.
For more insights on building robust systems, check out more info about AI models and how they integrate into modern growth modeling.





")